Kvantitativní analýza textů žákovského korpusu CzeSL-SGT
SGS (2022), SGS06/FF/2022
Miroslav Kubát, Radek Čech, Michaela Hanušková, Michaela Nogolová, Markéta Guńková
Projekt se zaměřuje na kvantitativní analýzu textů žákovského korpusu CzeSL-SGT. Cílem je získat základní data o textech jednotlivých jazykových úrovní a sledovat tak proces učení se češtiny jako cizího jazyka. Zabýváme se indexy slovního bohatství a syntaktické komplexity. Zajímá nás zejména vývoj napříč jednotlivými jazykovými úrovněmi a také rozdíl mezi vývojem slovanských a neslovanských rodilých mluvčích.
Kontakt: michaela.hanuskova@osu.cz, nogolovam@gmail.com
Lexikální diverzita
Lexikální diverzita (LD) je jedním ze způsobů, jak analyzovat slovní bohatství, specificky rozmanitost slov ve zkoumaném vzorku. LD se v oblasti akvizice jazyka analyzuje pomocí mnoha indexů. Na základě nejnovějších studií je jedním z nejspolehlivějších indexů MATTR (Moving-average type-token ratio), který využíváme i pro naši analýzu.
Cílem této analýzy je zjistit, jakým způsobem se vyvíjí lexikální diverzita textů psaných nerodilými mluvčími češtiny a zda se tento vývoj liší v závislosti na rodném jazyku pisatele.
Jazykový materiál je tvořen vybranými texty žákovského korpusu CZeSL-SGT, který je součástí Českého národního korpusu. Tento korpus je složen z písemných prací nerodilých mluvčích češtiny z let 2009 a 2013 a obsahuje více než 8000 autentických textů různých jazykových úrovní. Pro naši analýzu jsme využili 6073 textů. Z analýzy byly vyřazeny texty kratší než 55 slov a také jediný text s jazykovou úrovní C2. Také byly vyřazeny texty s nejasnou jazykovou úrovní.
| Jazyková úroveň | Počet textů | Počet textů slovanská skupina | Počet textů neslovanská skupina |
| A1 | 2024 | 1466 | 558 |
| A2 | 1838 | 1215 | 623 |
| B1 | 1371 | 879 | 492 |
| B2 | 722 | 511 | 211 |
| C1 | 118 | 80 | 38 |
Jednotlivé texty jsou analyzovány pomocí softwaru MATTR, okno pro analýzu klouzavého průměru je 50 slov. K porovnání výsledků mezi jednotlivými úrovněmi a také výsledků slovanských a neslovanských skupin na stejných úrovních jsou užity statistické testy. U výsledku s nenormálním rozdělením je užito Mann-Whitney testu a u výsledků s normálním rozdělením je užito t-testu. Statistické testy jsou vyhodnocovány na hladině významnosti 0,05.
Výsledky našeho výzkumu jsou zobrazeny na grafech 1 a 2.

V grafu 1 můžete vidět výsledky MATTR analýzy textů rozdělených do skupin podle jazykové úrovně pisatele. Napříč jednotlivými jazykovými úrovněmi je možné vidět stoupavou tendenci hodnot. Rozdíly hotnot jednotlivých statistických úrovní byly statisticky testovány pomocí Mann-Whitney testu. Výsledky statistických textů najdete v tabulce 2. Rozdíly mezi hodnotami jazykových úrovní jsou statisticky významné.
| A1 | A2 | B1 | B2 | |
| A2 | <0,0001 | – | ||
| B1 | <0,0001 | <0,0001 | – | |
| B2 | <0,0001 | <0,0001 | <0,0001 | – |
| C1 | <0,0001 | <0,0001 | <0,0001 | <0,0001 |

Na základě analýzy se nám potvrdil také předpoklad, že mluvčí se slovanským mateřským jazykem budou dosahovat vyššíh hodnot MATTR napříč všemi jazykovými úrovněmi. Rozdíl mezi slovanskými a neslovanskými rodilými mluvčími je na úrovních A1-B2 statisticky významný. Výsledky z této analýzy můžete vidět v grafu 2. Výsledky statistických testů můžete vidět v tabulce 3.
| A1 N x A1 S | <0,0001 |
| A2 N x A2 S | <0,0001 |
| B1 N x B1 S | <0,0001 |
| B2 N x B2 S | <0,001 |
| C1 N x C1 S | > 0,05 |
Syntaktická komplexita
Měření syntaktické komplexity má v analýzách druhého jazyka dlouhou tradici. Existuje mnoho indexů, které se užívají k prozkoumání syntaktické struktury. V naší analýze užíváme tyto:
- Průměrná délka věty (ASL)
- Počet slov textu vydělen počtem vět.
- Průměrná délka klauze (ACL)
- Počet slov textu vydělen počtem klauzí.
- Celková komplexita věty (CS)
- Počet klauzí textu vydělen počtem vět.
Cílem této analýzy je ověřit předpoklad – čím vyšší je jazyková úroveň, tím větší je v průměru ASL, ACL a také CS. Dále nás zajímá, zda se objevují rozdíly v závislosti na mateřském jazyce, konkrétně zda se objevuje rozdíl výsledků těchto měr na stejných úrovních u nerodilých mluvčích se slovanským a s neslovanským mateřským jazykem.
Jazykový materiál je tvořen vybranými texty žákovského korpusu CZeSL-SGT, který je součástí Českého národního korpusu. Tento korpus je složen z písemných prací nerodilých mluvčích češtiny z let 2009 a 2013 a obsahuje více než 8000 autentických textů různých úrovní znalosti jazyka. Pro tuto analýzu jsme zvolili pouze úrovně A1–C1, neboť úroveň C2 obsahuje pouze jeden text. Dále byly vyloučeny texty, které neobsahovaly ani jedno správně užité verbum finitum, a texty s nejasnou jazykovou úrovní. Celkově tedy v této analýze pracujeme se 7040 texty. V tabulce 1 můžeme vidět rozložení textů ve všech zde užívaných jazykových úrovní a také jejich zastoupení ve slovanských a neslovanských skupinách.
| Jazyková úroveň | Počet textů | Počet textů slovanská skupina | Počet textů neslovanská skupina |
| A1 | 2599 | 1780 | 819 |
| A2 | 2094 | 1346 | 748 |
| B1 | 1480 | 929 | 551 |
| B2 | 745 | 523 | 222 |
| C1 | 122 | 82 | 40 |
Jednotlivé texty jsou zpracovány pomocí anotačního nástroje UDPipe 2.0. Tento nástroj nám umožňuje identifikovat věty a klauze k následné analýze. K porovnání výsledků mezi jednotlivými úrovněmi a také výsledků slovanských a neslovanských skupin na stejných úrovních jsou užity statistické testy. U výsledku s nenormálním rozdělením je užito Mann-Whitney testu a u výsledků s normálním rozdělením je užito t-testu. Statistické testy jsou vyhodnocovány na hladině významnosti 0,05.
Na obrázcích 1, 2 a 3 můžeme vidět výsledky ASL, ACL a CS jak daných jazykových úrovní, tak také slovanských a neslovanských skupin.
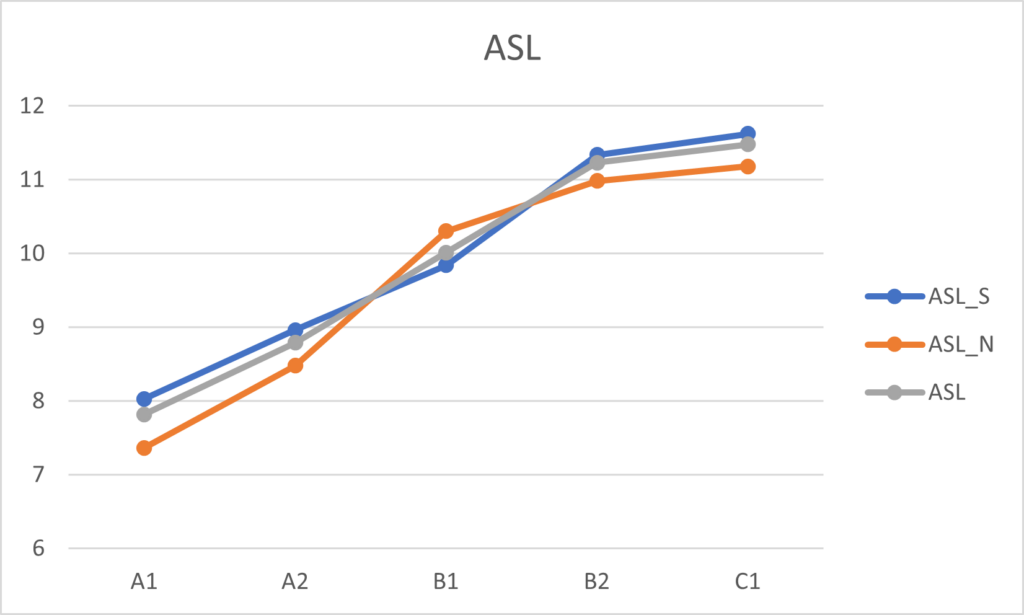
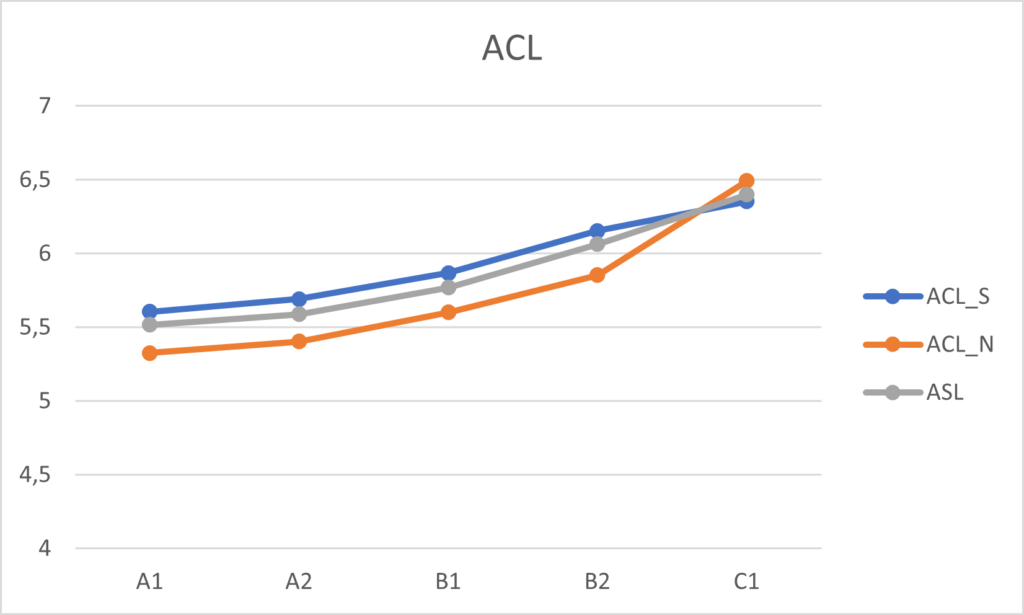
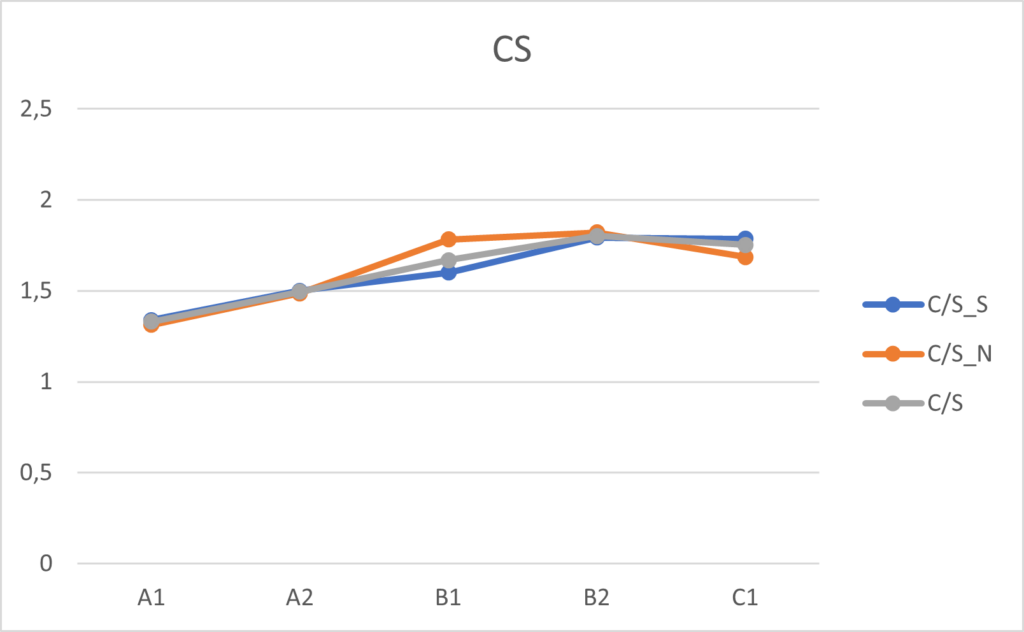
U všech tří indexů lze vidět rostoucí tendenci. Mezi slovanskými a neslovanskými skupinami můžeme vidět největší rozdíly u ASL a ACL. Ve většině případů mají slovanské skupiny vyšší průměrné hodnoty. Pouze u úrovně B1 v rámci ASL a C1 v rámci ACL dosahují neslovanské skupiny vyšších průměrných hodnot. Index CS poté při porovnávání průměrných hodnot slovanských a neslovanských skupin nevykazuje značné rozdíly, výjimkou je opět úroveň B1, kde neslovanská skupina dosahuje vyšší průměrné hodnoty.
V tabulce 2, 3 a 4 můžeme vidět výsledky statistických testů jednotlivých jazykových úrovní.
| ASL | A1 | A2 | B1 | B2 |
| A2 | <0,01 | |||
| B1 | <0,01 | <0,01 | ||
| B2 | <0,01 | <0,01 | <0,01 | |
| C1 | <0,01 | <0,01 | <0,01 | 0,18 |
| ACL | A1 | A2 | B1 | B2 |
| A2 | <0,01 | |||
| B1 | <0,01 | <0,01 | ||
| B2 | <0,01 | <0,01 | <0,01 | |
| C1 | <0,01 | <0,01 | <0,01 | 0,02 |
| CS | A1 | A2 | B1 | B2 |
| A2 | <0,01 | |||
| B1 | <0,01 | <0,01 | ||
| B2 | <0,01 | <0,01 | <0,01 | |
| C1 | <0,01 | <0,01 | <0,01 | 0,93 |
Výsledky statistických testů ukázaly statisticky signifikantní rozdíl mezi všemi úrovněmi, vyjma úrovní B2 a C1 u ASL a CS. U ACL byly statisticky významné rozdíly mezi všemi úrovněmi.
V tabulce 5 jsou poté výsledky statistických testů mezi slovanskými a neslovanskými skupinami.
| S. vs. N | ASL | ACL | CS |
| A1 | <0,01 | <0,01 | <0,01 |
| A2 | <0,01 | <0,01 | <0,01 |
| B1 | 0,74 | <0,01 | <0,01 |
| B2 | 0,02 | <0,01 | 0,84 |
| C1 | 0,49 | 0,67 | 0,19 |
Výsledky ASL u slovanských a neslovanských skupin vykazují statisticky významné rozdíly ve většině úrovní kromě B1 a C1. V rámci ACL nebyla statisticky významná pouze skupina C1 a u indexu CS jsou statisticky významné rozdíly v úrovních A1–B1.